Figur 1. Olika kommunikationsnivåer
Magnus Cedergren (ceder@nada.kth.se)
Interaktions- och presentationslaboratoriet
Inst. för Numerisk analys och datalogi
Kungl. Tekniska högskolan
100 44 Stockholm
Datorn som skrivhjälpmedel för de nämnda yrkesgrupperna har inneburit en förändrad arbetsuppdelning på kontoren. Det är inte längre en noggrann och språkkunnig sekreterare som lägger sista handen vid alla dokument. Texten ändras ofta av författaren själv ända fram till "deadline". Denna förändring har potentiellt både positiva och negativa konsekvenser. Den ökade användningen av ordbehandling har inneburit ett ökat behov av datorstöd för att kontrollera och hantera språkliga egenskaper hos texter.
Denna rapport föreligger som ett delresultat inom projektet "Språkliga datorstöd vid skrivande" vid NADA/IPLab, Interaktions- och Presentationslaboratoriet, Inst. för numerisk analys och datalogi vid KTH. Inom detta projekt försöker vi med skribenten som utgångspunkt undersöka möjligheterna för datorn att på olika vis stödja skribenten språkligt. Med språkkunskap kan datorn utföra en mängd olika uppgifter: Granska texter (genom t.ex. läsbarhetsanalyser eller rättstavning), avstava eller kanske stödja skribenten att formulera och redigera texten. Vidare utvecklas en programprototyp, Plita, i HyperCard på Apple Macintosh. Projektet har finansierats av Apple Computer Svenska AB och av NUTEK (Närings- och teknikutvecklingsverket).
Skrivforskningen vid NADA/IPLab knyts till ett skrivlaboratorium som håller på att byggas upp. Forskningen inom detta laboratorium rör vitt skilda aspekter av skrivandet. Projekten som f.n. bedrivs vid laboratoriet, förutom de språkliga datorstöden, rör bl.a. undersökningar av problemen kring överblick vid skrivande med dator, grundläggande metoder för att studera skrivprocessen med datorstöd samt datorstött kunskapssamarbete med hypertext-teknik som datorstöd. En del forskning ägnas också datorstödd typografisk formgivning.
Jag vill här tacka Apple Computer Svenska AB, Jorge de Sousa Pieres och NUTEK, Gunnel Tolby/Ulf Eklundh som finansierat projektet samt min projektledare Kerstin S. Eklundh för många värdefulla råd under skrivandets gång.
Magnus Cedergren
Metoder för att förutsäga läsbarheten kan antingen vara textbaserade, enbart mätningar av textens språkliga kvalitéer, t.ex. läsbarhetsformlerna, eller text/läsarbaserade, mätningar av läsarens relation till texten. Några text/läsarbaserade mätmetoder beskrivs i avsnitt 3.
I avsnitt 4 beskrivs sedan läsbarhetsformlerna, alltifrån de första amerikanska försöken före andra världskriget till de aktuella svenska formlerna Lix och KIX. Jag diskuterar också användningen av datorer för att beräkna läsbarheten samt återger en del av den omfångsrika kritik formlerna och deras tillämpningar utsatts för.
Med utgångspunkt från kritiken har somliga formelkonstruktörer försökt skapa nya och mer sofistikerade läsbarhetsformler. Många av dessa försöker kvantifiera grammatiska storheter i texten. Metoder för att mäta sammanhang och syntaktisk komplexitet är några av dessa alternativa metoder som diskuteras i avsnitt 5.
"Läsbarheten är summan av sådana språkliga egenskaper hos en text, vilka gör den mer eller mindre svårtillgänglig för läsaren."
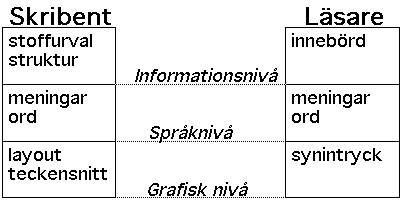
Björnsson skiljer läsbarheten ifrån läslighet och läsvärde hos en text. Läslighet definierar Björnsson som de typografiska egenskaperna hos texten, såsom t.ex. val av teckensnitt, radlängd, eller det fysiska avståndet mellan stycken. Läsvärde är, enligt Björnsson, hur komplexa eller intressanta de innehållsmässiga aspekterna av texten är.
Roland Larsson [Larsson 1987] redovisar de tre begreppen i en nivåskiktad struktur. Den typografiska nivån, läsligheten, och den språkliga nivån, läsbarheten, ligger som grund för att textens innebörd, läsvärdet, skall nå fram till läsaren, figur 1.
Figur 1. Olika kommunikationsnivåer
För en översikt över litteratur på området läsligheten hos text på datorskärmar hänvisas till [Frenckner 1990]. Den här framställningen behandlar alltså läsbarheten och dess tillämplighet för datorstöd.
Det finns flera metoder för att förutsäga läsbarhet. [Rush 1985] delar in dessa metoder i rent textbaserade metoder och text/läsarbaserade metoder. De rent textbaserade metoderna innebär att texten studeras rent objektivt, t.ex. genom att räkna meningslänger och ordlänger. De text/läsarbaserade metoderna, däremot, innebär att någon form av referensgrupp engageras när man vill bestämma läsbarheten hos dokumentet.
I detta avsnitt följer en kortfattad genomgång av några av de text/läsarbaserade metoderna, som av naturliga skäl inte helt kan automatiseras och delvis ligger utanför ramen för denna framställning. Jag väljer dock att summera dem eftersom somliga av dessa metoder ibland har använts för att verifiera läsbarhetsformler eller andra rent textbaserade metoder. De rent textbaserade metoderna följer sedan alltså i avsnitt 4.
Denna skalas jämna värden har dock ifrågasatts och värdena bör naturligtvis inte betraktas som alltför exakta.
Rauding-skalan består av sex mindre malltexter motsvarande sex olika årskursnivåer: 2, 5, 8, 11, 14 och 17. För att använda Rauding-skalan läser man först igenom texten som skall klassas. Därefter bestämmer man två av malltexterna som mest liknar denna text ur läsbarhetssynpunkt. Tre faktorer tas här under övervägande: Hur vanliga orden som används är, hur komplex idén som presenteras är samt hur invecklade meningarna är. Därefter fastställs årskursnivån.
SEER-tekniken består av två stycken likvärdiga skalor: Standardskala I och standardskala II. Dessa består var och en av åtta malltexter mellan årskurs 1,5 och 6,5 resp. 6,8. Texten som skall årskursbestämmas jämförs med texterna i de två skalorna och två stycken värden fastställs. Det slutliga värdet räknas fram som ett medel av de två skalorna.
Skalorna på SEER-teknikens texter baseras på beräkningar med hjälp av några traditionella läsbarhetsformler, varför den i första hand skall betraktas som ett praktiskt alternativ till läsbarhetsformler vid manuell beräkning (jfr. avsnitt 4.4).
Principen med lucktester är att välja en eller flera lagom långa utdrag ur den aktuella texten. Därefter ersätts ord av en lucka i ett regelbundet intervall. Det är t.ex. vanligt att låta var femte ord ersättas av en lucka.
Slutligen får ett antal försökspersoner försöka fylla i luckorna med de ord som stod där ursprungligen. Som mätresultat av dessa försök erhålls den andel av luckorna som försökspersonerna lyckades fylla i korrekt. En vanlig acceptans, t.ex. i Dale-Calls formel (avsnitt 4.2), är att 50% av luckorna fyllts i korrekt. Då, menar man, kan den tänkta målgruppen tillgodogöra sig texten på ett bra sätt.
De allmänna principen för att konstruera en formel är vanligen sedan denna:
Efter att ha valt ut ett begränsat antal variabler som skall ingå i formeln jämförs en beräkning av dessa variabler med resultaten från någon referensmetod. Som sådan används t.ex. någon av de text/läsarbaserade mätmetoderna (avsnitt 3) eller McCall-Crabbs standard testlektioner för läsning. Dessa har enligt [Klare 1974/75] använts för flera av de äldre kända formlerna (se nedan). Dessa testlektioner finns vidare i flera upplagor (t.ex. 1925, 1950 och 1961, Klare), men var ursprungligen inte avsedda för konstruktion av läsbarhetsformler. Att formelkonstruktörer har använt denna verifikationsmetod för många av formlerna kan därför tolkas som en svaghet [Olson 1984].
Med hjälp av en multipel korrelationsanalys erhålls regressionskoeffecienter till de ingående variablerna samt vanligen en konstant. Vidare erhålls en korrelationkoeffecient som anger hur väl formelvärdena från beräkningarna stämmer överens med referensmetodens värden.
Det har diskuterats om formlerna enbart kan användas på större texter -- eller åtminstone på urval ur större texter -- eller om det går bra att applicera dem på enstaka meningar eller ord. [Bormuth 1969] kom i sina omfattande studier fram till att det i många fall går bra att applicera formlerna just på så små enheter som enstaka meningar och ord, likaväl som på större textmängder.
Sherman på 1890-talet och Kitson på 1920-talet sammanfattade några väsentliga grunder för vad som gör en text lättläst, utan att själva konstruera några läsbarhetsformler. Deras respektive slutsatser har legat som grund för de formler som senare utvecklats.
Sherman kom fram till att följande tre faktorer påverkar läsbarheten positivt:
Sherman menade vidare att det går bra att göra läsbarhetsberäkningar enbart på en del av texten i stället för att göra det på hela texten.
Kitson banade väg för en hel mängd läsbarhetsformler under 1920-talet genom att dra följande två slutsatser: Kortare genomsnittlig meningslängd och kortare genomsnittlig ordlängd förenklar läsbarheten hos en text.
Irving Lorges läsbarhetsformel från 1939 är den mest kända av de tidiga formlerna. Den bestod av tre komponenter: genomsnittlig meningslängd, andel prepositionsfraser och andelen svåra ord (som inte fanns med Dales lista över svåra ord [Klare 1974/1975]).
1943 publicerade Rudolf Flesch sina första formler. Hans första formel innehåller tre komponenter: Antal ändelser, genomsnittlig meningslängd samt antal personliga referenser. Flesch konstruerade flera formler och det är hans två formler från 1948 som är mest välkända, "Reading Ease" (R.E.) och "Human interest" (H.I.). Det är särskilt R.E. som blivit mycket spridd.
R.E. = 206,835 - 0,846 wl + 1,015 sl
H.I. = 3,635 pw + 0,314 ps
wl = antal stavelser per 100 ord
sl = genomsnittligt antal ord per mening
pw = antal personord per 100 ord
ps = antal personliga meningar per 100 meningar
R.E. korrelerade 0,70 med McCall-Crabbs testlektioner och H.I. 0,43. Fleschs formler har räknats om flera gånger, vilket har resulterat i delvis andra koefficienter.
Dale och Calls formel från 1948 för texter skrivna av vuxna tillhör också de mera välkända:
Xs = 0,1579 xa + 0,0496 xb + 3,6365
Xs = antal årskurser hos en läsare som svarar hälften rätt på testfrågor på passagen
xa = Dales värde, eller andel ord utanför Dales lista med de 3000 vanligaste orden
xb = genomsnittlig meningslängd
Dale-Calls formel utgår, liksom Fleschs formler, från McCall-Crabbs testlektioner. Liksom Fleschs R.E. korrelerade även Dale-Calls formel 0,70.
Robert Gunnings Fog index från 1952 är en annan välkänd läsbarhetsformel. I stället för att räkna stavelser som i Fleschs R.E. räknar Gunning den procentuella andelen komplicerade ord, som han definierar som alla ord med minst tre stavelser:
Reading grade level = 0,4 x (genomsnittlig meningslängd +
procentuell andel av ord med 3 eller fler stavelser)
En nyare formel som fått stor spridning, särskilt för datorberäkningar, är J. Peter Kincaids formel [McClure 1987]. Den skrevs ursprungligen för att mäta läsbarheten hos den amerikanska flottans tekniska instruktionsböcker:
Reading grade level = 0,39 x (ord/mening) + 11,8 (stavelser/ord) - 15,59
Kincaids formel har dock visat måttligt goda resultat vid verifieringar utförda på elever inom den amerikanska flottan (korrelation 0,49) [Losa et.al 1983], men visat mycket goda resultat vid implementationen i programsystemet WWB (avsnitt 4.5.1).
Ord per mening: 25
Ord per interpunkterad paus: 12
Ord per stycke: 75
Stavelser per 100 ord: 150
Morris redovisar inte, enligt Klare, någon form av verifikation för sina värden.
ELF = antal stavelser per ord i en mening fler än en
Fang verifierade ELF i första hand med manuskript från nyhetsuppläsningar i TV. Han hittade en korrelation på 0,96 mellan ELF och Fleschs R.E.
Tillsammans med presentationen en ny formel följde ofta detaljerade beskrivningar över hur formeln i praktiken skall tillämpas. Redan Flesch publicerade t.ex. 1951 [Klare 1974/75] ett diagram för fastställning av läsbarhet enligt hans R.E. och H.I.-formler.
Det har även förekommit rekommendationer om andra hjälpmedel för manuella läsbarhetsberäkningar. Kincaid och McDaniel [Klare 1974/75] presenterade en metod för att använda en elektronisk metronom med räknare som stöd för manuell beräkning.
Edvard Frys läsbarhetsgraf [Fry 1968, 1977] är ett annat exempel på en praktiskt användbar metod för beräkning av läsbarhet. Frys graf består, liksom de flesta övriga formlerna av två komponenter: Genomsnittligt antal meningar per 100 ord och genomsnittligt antal stavelser per 100 ord. Till skillnad från de vanliga formlerna försöker inte Fry linjarisera förhållandet mellan årskurser och de två ingående komponenterna, utan ritar upp en graf med resultaten från sina mätningar. Grafen har de två ingående komponenterna på var sin axel. Med hjälp av sina mätvärden konstruerade Fry sedan en genomsnittskurva i grafen kring vilken de flesta värdena i praktiken ligger. Vad som skiljer Frys graf från de övriga formlerna är att denna kurva alltså inte kan liknas vid en linjär kurva, utan snarare vid en avtagande exponentiell kurva. En vidareutveckling av Frys graf skulle alltså kanske kunna leda till en läsbarhetsformel innehållande ett exponentiellt uttryck.
I [Fry 1989] redovisas en annan enkel metod, avsedd särskilt för mycket korta urval av texter. I denna metod väljs ett antal nyckelord ut som skall representera texten. Av dessa väljs tre ut ytterligare en gång och deras genomsnittliga längd utgör ordfaktorn. Meningsfaktorn i denna metod är enbart relaterad till den genomsnittliga meningslängden och avläses i en tabell. För att slutligen erhålla årskursnivån på texten tas snittet av ordfaktorn och meningsfaktorn.
Datorer för beräkning av läsbarhet har öppnat flera nya möjligheter. Datorerna kan hantera stora beräkningar, t.ex. av en hel bok i stället för väl valda delar av den (jfr. avsnitt 4.4). Det har vidare börjat dyka upp formler som manuellt kräver stora beräkningar (t.ex. med många variabler) men som lämpar sig väl för datorberäkningar. Med datorerna öppnar sig slutligen nya möjligheter vad gäller presentationen av beräkningsresultaten.
I de flesta program av typen "Grammar&Style-checkers" görs läsbarhetsberäkningar. Dessa program redovisar i allmänhet två kategorier av resultat. Dels anger programmen resultaten av läsbarhetsberäkningar enligt några kända formler, dels redovisas en mängd andra kvantitativa mått på texten, t.ex. meningslängd, ordlängder, antal pronomen, antal passiva fraser etc. I bilaga A redovisas några olika datorprogram som vi utvärderat vid IPLab och de kvantitativa mått och läsbarhetsformler som dessa program presenterar. Somliga av programmen är kommersiella program, medan andra är s.k. Freeware/Shareware. En enkel utvärdering av några av programmen redovisas i avsnitt 4.5.2.
Trots att läsbarhetsformlerna generellt passar bra för datorberäkningar är det inte alltid självklart hur dessa beräkningar skall utföras. Något om dessa problem finns i [Spiegel&Campbell 1985]: Vad är en mening och hur definieras meningslängd? Man kan inte ens helt entydigt definiera vad som är ett ords "riktiga" längd. Hur gör man t.ex. med förkortningar och sifferuttryck?
Spiegel&Campbells största problem var dock att definiera antalet stavelser för en engelsk text. De hittade inget enkelt och tillfredställande svar på detta problem, utan lät datorn i stället räkna antalet bokstäver i orden och via det approximera antalet stavelser vid beräkning av Fleschs R.E. För svenska är dock just detta problem mindre: Varje stavelse motsvarar exakt en vokal i de allra flesta fall. För svenska räcker det alltså att räkna antalet vokaler.
Programmet STYLE [Cherry 1981] -- vilket är en del av programsystemet Writer`s Workbench (WWB) -- beräknar läsbarhetsvärden samt en rad andra kvantitativa mått, se vidare bilaga A. Cherry redogör i sin rapport något om sina slutsatser angående datorbaserade beräkningar av läsbarhetsformler. Hon påpekar bl.a. att Kincaids formel tenderar vara den mest användbara för teknisk dokumentation av de formler som ingår i STYLE.
Resultaten verkar överenstämma bra i de fall där samma formel använts på samma text, men beräknade i olika program. Flesch R.E. som beräknas av Correct Grammar, Gram*ma*tik Mac, Maxi Read och Word Count (WC) skiljer sig endast några procent mellan de olika programmen. Motsvarande gäller även för Flesch-Kincaid som beräknas av Correct Grammar och Gram*ma*tik Mac. Dessutom överensstämmer årskursnivån från Gunnings Fog Index väl med årskursnivån från Flesch-Kincaid i Correct Grammar.
Gunnings Fog Index överenstämmer dock mindre väl mellan programmen Gram*ma*tik Mac och Word Count (Macintosh). Detta visar att beräkningsgrunderna inte alltid är helt självklara och programmet Word Count förefaller inte använda riktigt samma beräkningsgrunder som de övriga programmen (jfr. föregående avsnitt).
I motsats till att många formler förenklats för att underlätta manuell användning, har somliga gjorts mer sofistikerade enbart avsedda för automatiserat bruk. Allt eftersom datorerna blev snabbare och kraftfullare kunde också formlernas komplexitet öka. I [Klare 1974/75] nämns ett försök till en mer komplicerad formel avsedd för en dator att beräkna. Programmet READSCORE består fem skilda variabler, alla viktade med en regressionskoeffecient:
Denna utveckling representeras också av Bormuths studier [Bormuth 1969]. Dessa är de mest omfattande studier av läsbarhetsformler som gjorts. Bormuth testade en lång rad lingvistiska variabler, såsom t.ex. orddjup (t.ex. i ett parseträd), men också variabler som traditonellt använts i läsbarhetsformlerna: ordlängd, meningslängd, ord som förekommer i listor över vanliga ord etc. Bormuth erhöll hög korrelation för somliga variabler och lägre för andra. Han menade att ännu bättre formler än de existerande kan konstrueras, genom en kombination av rätt variabler. Precis som Fry implicit konstaterat ovan (avsnitt 4.4.1) kunde Bormuth konstatera att icke-linjära formler kanske skulle kunna ge bättre resultat än de linjära formlerna.
[Duffelmeyer 1985] påpekar att användaren trots detta, precis som tidigare, måste ta exaktheten i dessa värden med en nypa salt. De flesta årskursgraderade formlerna kan enligt konstruktörerna slå fel med en hel årskurs upp eller ned. För Lix-formeln (avsnitt 4.6.1) skulle det uppskattningsvis motsvara i storleksordningen 5 enheter upp eller ned.

Figur 2. Lix-värden presenteras med cirkeldiagram i programprotypen Plita
De två programmen Grammatik Mac och Sensible grammar (se Bilaga A) presenterar resultaten från sina läsbarhetsberäkningar med hjälp av ett liggande stapeldiagram resp. en linjalskala.
I min egen programprototyp Plita presenteras en rad kvantitativa mått, däribland Lix-beräkningar (Lix, se nedan) med hjälp av presentationsgrafik. Med hjälp av cirkeldiagram, stapeldiagram och punktdiagram kan användaren förhoppningsvis lättare och snabbare tillgodogöra sig den sifferbaserade informationen.
Lix formeln är dock inte ensam representant utanför det engelska språkområdet. [Klare 1974/75] redovisar en lång rad läsbarhetsformler för andra språk än engelska, däribland för franska, holländska, spanska, hebreiska, tyska, hindi, ryska och kinesiska. Dessa formler är dels lokala anpassningar av amerikanska formler, t.ex. Fleschs R.E., men också i flera fall helt egna formler. Språk med egna teckensystem, som hebreiska och kinesiska dialekter, kräver naturligtvis andra utgångspunkter än de formler som är utvecklade för det latinska alfabetet.
Liksom de amerikanska formlerna består Lix av en komponent för meningslängd, som på något vis skall motsvara syntaktisk svårighetsgrad, och en komponent för ordlängd, som beskriver semantisk svårighetsgrad:
Lix = Antalet ord / Antalet meningar + 100 * Antalet svåra ord / Antalet ord
Svåra ord definierar Björnsson som alla ord som består av mer än sex bokstäver.
Lix saknar alltså regressionskoeffecienter och i stället behövs tolkningstabeller, särskilda "Lix-tolkar". Genom omfattande studier för olika typer av text har Björnsson erhållit flera olika typer av Lix-tolkar beroende på användningsområde. Den sådan, generell Lix-tolk ser ut på följande sätt [Larsson 1987]:
Genom att Lix kan tolkas på olika sätt i olika sammanhang kan den också användas för texter både från vuxna skribenter och skolelever. På motsvarande sätt kan den också för andra språk än svenska. I [Björnsson 1983] jämförs Lix-värden på tidningstexter på elva olika språk. [Bamberger&Rabin 1984] beskriver årskursgraderade Lix-tolkar för tyska, en särskild för skönlitteratur och en annan för facklitteratur.
Jonathan Anderson, Flinders University of South Australia, har använt Lix för läsbarhetsvärdering av texter [Anderson 1981] på bl.a. franska och engelska och erhöll ungefär samma goda korrelation som vid användning av Fleschs R.E.
Rix = 100 x Antalet svåra ord / Antalet meningar
Ordfaktorn, antalet svåra ord, och meningsfaktorn, antalet meningar, bildar i Rix-formeln en kvot, till skillnad mot Lix-formeln där de bildar en summa. Ett svårt ord definieras, precis som är fallet för Lix-formeln, som alla ord med fler än sex bokstäver.
Rix-formeln är avsedd att vara manuellt lättberäknad. För att beräkna ett Rix-värde för en text räcker det med att räkna dels antalet brytpunkter för nya meningar, dels antalet svåra ord. Storheten antalet ord som förekommer i Lix-formeln kräver mest arbete vid manuell beräkning. Denna storhet har av praktiska skäl alltså eliminerats i Rix-formeln.
Rix-formeln är i första hand avsedd för bruk i pedagogiska sammanhang. I en tabell tolkar Anderson Rix-värdena som årskurser. Denna tabell är inte strikt linjär, utan 10 motsvarar t.ex. årskurs 1, 210 årskurs 6 och 670 årskurs 12.
De rent praktiska motiven att använda Rix-formeln faller dock vid datorstödd beräkning av läsbarhetsvärden. De rena ortografiska storheterna, som både Rix-formeln och Lix-formeln består av, är alla lätta för en dator att beräkna.
KIX-metoden kan inte beskrivas genom ett enda formeluttryck. Nedan följer därför en kortare matematisk beskrivning av KIX-metoden hämtad ur [Larsson 1987], tillsammans med de antaganden som Larsson gör implicit.
L = x + 100 * y/x (1)
L = Lixvärde
x = genomsnittligt antal ord per mening
y = genomsnittligt antal långa ord per mening i texten
görs följande härledning:
Om (1) betraktas som en funktion där y beror av x och L, erhålls följande "Lix-parabel":
y = x (L - x) / 100 (2)
Här gör Larsson antagandet att ett maximum av denna funktion är eftersträvansvärt, dvs. att det genomsnittliga antalet långa ord per mening skall vara så stort som möjligt vid ett fixt Lixvärde. Larsson menar att skribenten får betala ett "pris" om han vill förmedla ett långt, innehållsbärande ord till läsaren. y-variabeln i (2) är maximal då
x = L/2 (3)
och
y = L2 / 400 (4)
Larsson räknar utifrån (3) fram "idealkurvan", utmed vilken texter med ett bestämt lixvärde "bör" ligga:
y = x2 / 100 (5)
Nästa antagande baserar sig, delvis, på kognitiva fakta: Hjärnan klarar inte av att hantera fler än nio begrepp samtidigt, därför klarar den heller inte fler än nio långa ord i en mening samtidigt, enligt Larsson. Genom detta antagande erhålls en "varningskurva" ur (2) om man fixerar y=9 och därmed x=60 (erhålls ur (4)):
y = x (60 - x) / 100 (6)
Varningskurvan är en övre gräns över vilken lixvärdena, enligt antagandet, inte bör hamna för en text med god läsbarhet. Larsson "balanserar" det nu uppkomna området ovanför idealkurvan genom att konstruera ett lika stort område nedanför idealkurvan. Lixvärdena för de enstaka meningarna bör i möjligaste mån hamna inom dessa områden enligt antagandena.
Nu följer en hel mängd antaganden. Dessa de "tredje antagandena" samt de hittills beskrivna kurvorna illustreras i figur 3. De tredje antagandena består i att Larsson döper de områden som kurvorna indelar. Han delar dessutom in områdena ovanför och nedanför idealkurvan i ytterligare vardera tre områden, utan av tala om hur detta är härlett. De nio termerna Larsson på detta sätt introducerar är:
Vid användning av KIX-metoden motsvaras varje mening i texten av en punkt på KIX-diagrammet. Vilken av de nio verbala omdömena om texten som skall väljas beror på var "tyngdpunkten" för alla punkterna hamnar, dvs. var ansamlingen av punkterna hamnar i diagrammet.
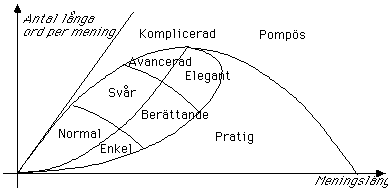
Figur 3. KIX-diagrammet
Med KIX-diagrammet som utgångspunkt, menar Larsson, att vi kan hitta "symptom" på var och en av dessa typer av vanliga fel. Exempelvis visar alltför många punkter uppe till vänster i diagrammet (korta meningar, stor andel långa ord) symptom på att texten innehåller nominaliseringar eller "substantivsjuka".
Larsson påstår alltså att KIX dels kan ge en stilmässig bedömning av texten, dels hitta symptom på grammatiska svagheter hos texten.
Programmet finns även i en amerikansk version under namnet "Corporate Voice" [Larsson&Frankel 1990] (tidigare "Readability" [Hensinger 1988]) där KIX-metoden baseras på Gunnings fog index i stället för som i det svenska programmet där Lix-formeln ligger som grund. Detta program är en vidareutveckling av det ursprungliga, svenska programmet. Användaren har i detta program större möjligheter att själv lägga till mallar i KIX-diagrammet etc. Programmet har gjort succé på de amerikanska marknaden, recension se [Rash 1991].
[Svensson 1989], som skriver om läsbarhetsformlernas användning på barnlitteratur, delar in kritiken mot läsbarhetsformlerna i tre grupper:
Svensson framhåller dessutom vikten av att i de här sammanhangen skilja tillämpningarna av formlerna från själva formlerna.
Den estetisk-litterära kritiken rör bl.a. författarens konstnärliga frihet. vilket inte några formler "bör" lägga band på. Lässituation är dessutom mer än bara en avkodning av ord och meningar, påpekar Svensson. För att ha full behållning måste läsaren kunna hantera ironier, metaforer, olika tonlägen hos berättaren etc. Detta går inte alls att mäta med de traditionella läsbarhetsformlerna. Svensson refererar dessutom till senare tiders forskning om skönlitterär läsning. Även läsaren, inte bara författaren, skapar på ett mycket personligt vis under läsningen.
Den pedagogiska kritiken rör motivation, dels motivation för ämnet i texten, dels motivation för läsandet som sådant. En enligt läsbarhetsformlerna svår text kan bli en "munsbit" för en läsare, bara vederbörande är tillräckligt motiverad.
Detta att förbättra en befintlig text, är en av grundvalarna för definitionen av KIX-metoden (avsnitt 4.6.3), varför denna metod t.ex. inte kan stå emot denna kritik.
[Backman 1976] menar Björnsson talar emot sig själv vad gäller användningen av Lix-formeln i detta avseende. Dels säger Björnsson att formeln enbart skall användas på "naturliga" texter och inte på "manipulerade texter", dels säger han att man skall "variera meningslängden när man skriver om texten".
Backman kritiserar vidare själv formlerna och påstår de enbart mäter trycksvärta. Han ger även underbetyg åt formelkonstruktörernas verifikationsmetoder, t.ex. lucktester och kunskapsprov. Backman efterlyser i stället metoder att subjektivt förutsäga texters påverkan på kognitiva processer.
De traditionella formlerna är alltså lätta att automatisera. För de nedan beskrivna metoderna är detta inte alltid lika lätt. I många fall krävs skilda nivåer av automatisk grammatisk analys.
AFL = X/Y
AFL = genomsnittligt frekvensnivå
X = totalt antal nivåer från NZCER-listan över alla substantiv i texten
Y = totalt antal substantiv i texten
Elleys substantivfrekvenser passar bra för datorstödda beräkningar. I och med den beränsade NZCER-listan behövs en analys göras liknande den som görs vid rättstavningskontroll.
Likt Bormuth är Bambergers och Rabins studier omfattande. Likheterna med att undersöka en hel rad faktorer är också uppenbar. Skillnaden från Bormuth ligger framförallt i tolkningen av materialet. Österrikarna Bamberger och Rabin tolkar varje enskild faktor för sig. Vid användning av en språkprofil erhålls ett särskilt årskursvärde för varje enskild faktor för sig. En text kan t.ex. motsvara årskurs 8 vad gäller meningslängd och årskurs 6 vad gäller andelen enstaviga ord.
Presentationen från en språkprofil blir naturligen mer omfångsrik än en ordinär läsbarhetsformel. Dessutom medför en manuell användning en sådan profil mycket arbete. Enligt konstruktörerna är därför beräkningar av dessa faktorer i första hand avsedda att genomföras med datorstöd.
Whitney menar att man genom att mäta de nio faktorerna kan ange hur "hård", "mjuk" och "dämpad" texten är. De flesta texter kan alltså betraktas som en kombination av de tre typerna av skribenter. Själva viktningen av faktorerna återstår dock att göra.
En datorbaserad beräkning enligt Whitneys metod kräver delvis endast enkla, ortografiska beräkningar -- som i de traditionella formlerna -- medan andra kräver olika typer av grammatisk analys.
Omdömen om skribenten liknande de som Whitney föreslår görs i datorprogrammen RightWriter och PC-Style (Appendix A). De försöker ge bedömningar av typen beskrivande, personlig, händelserik etc. enbart genom att räkna ord av en viss typ (t.ex. en ordklass). Hur personlig texten är mäts t.ex. i andelen personliga pronomen, hur händelserik den är genom andelen innehållsbärande verb samt beskrivande i andelen adverb och adjektiv.
[Fry 1977] definierar kärna och periferi i sin "Kernel Distance Theory". Kärnan i en mening definierar Fry som subjekt, predikat och ibland ett objekt. Periferi är de ord som inte ingår i kärnan. Fry påstår sedan, vilket är en verifierad del av hans teori, att periferi inskjuten mellan subjekt och predikat gör meningen svårare. I teorien ingår två ytterligare påstående som, enligt Fry, inte verifierats: Periferi före kärnan gör en mening svårare än en mening med periferi efter kärnan, samt periferi mellan subjekt och predikat är svårare än periferi mellan predikat och objekt.
[Perkins 1982] refererar och försöker verifiera en skala för att mäta språklig stil utvecklad av Joseph Williams. Principen för denna skala är att det finns en koppling mellan de grammatiska begreppen subjekt, predikat och det semantiska begreppet agent och vad den gör.
Datorbaserade läsbarhetsberäkningar av syntaktisk svårighetsgrad kräver naturligen en datorbaserad syntaktisk analys. Resultaten av sådan datorstödd, grammatisk analys blir sällan fullständigt korrekt. För denna tillämpning torde det dock inte betyda så mycket eftersom det vanligen handlar om statistiska beräkningar på vissa syntaktiska komponenter.
Anderson analyserade tre korta texter med avseende på bindningar av dessa typer. Han räknade dels de grammatiska bindningarna (referenser, ersättningar och ellipser) dels de lexikala bindningarna i respektive text. Vidare uteslöt han konjunktionsbindningarna.
För jämförelsens skull genomförde han dessutom läsbarhetsmätningar enligt två andra metoder: Bedömning och läsbarhetsformel (RIX, beskrivs vidare i avsnitt 4.6.2). Anderson relaterar sedan det totala antalet bindningar till antalet ord. Vid jämförelse mellan denna relation och resultaten från de två andra mätmetoderna erhålles värden som är omvänt proportionella. När Anderson sedan relaterar bindingarna till antalet meningar erhålles däremot värden som är direkt proportionella.
Materialet är mycket litet, och Anderson menar att mycket forskning återstår att göras kring relationen mellan sammanhanget/bindningarna i en text och läsbarheten/förståelsen av den.
En datorstödd beräkning av antalet bindningar enligt ovan är kanske inte helt omöjlig. I varje fall de grammatiska bindningarna består tekniskt av en begränsad mängd av funktionsord. De lexikala bindningarna, däremot, kan bli svårare. Här krävs antagligen av datorn en mer fullständig semantisk analys.
De två senare kategorierna räknas, medan bindningarna i den första gruppen kvantifieras som avståndet mellan referens och referent (t.ex. mellan en nominalfras och ett pronomen).
Clark framhåller att hans PHAN-system inte ersätter läsbarhetsformlerna, utan i stället kompletterar dessa. Han menar att de traditionella formlerna vanligen mäter avkodning av texten, medan hans system mer mäter textförståelse.
Congleton försökte verifiera sin skala med bedömningar från kvalificerade bedömare. Resultatet gav en god korrelation (runt 0,9). Hon jämförde också mätningar med sin skala med Frys läsbarhetsgraf och fick här ingen god korrelation. Ur detta drog Congleton slutsatsen att hennes skala inte mäter samma faktorer som de traditionella läsbarhetsformlerna, utan i stället kan användas som ett komplement till dessa.
Congletons skala är av semantisk karaktär och det krävs kvanlificerade bedömare för att beräkna de metaforiska svårighetsgraden. Det kommer naturligtvis inom överskådlig tid att vara svårt att anpassa denna skala för datorberäkningar.
Det är också viktigt att minnas för vilka syften läsbarhetsformlerna i allmänhet skapades. Att t.ex. göra läsbarhetsberäkningar på skönlitterär text ger sällan trovärdiga resultat.
Med datorer och nya, mer sofistikerade metoder för läsbarhet kan morgondagens läsbarhetsprogram bli mer användbara:
Vid konstruktion av program som beräknar läsbarhetsvärden med hjälp av läsbarhetsformler är det vidare viktigt att vara nogrann i sin definition av ordlängder, meningslängder etc. Mitt försök (avsnitt 4.5.2) visar att alltför enkla program i bland kan ge felaktiga resultat.
[Bamberger&Rabin 1984] nämner slutligen flera tänkbara, rent nya, framtida forskningsområden: Metoder för att
ANDERSON, JONATHAN, 1983a: Lix and Rix: variations on a little-known readability index. Journal of Reading, no 26, 1983, pp 490-496
ANDERSON, JONATHAN, 1983b: Cohesion, Comprehending and Comprehensibility. Paper presented at the Annual Meeting of the International Reading Association (28th, Anaheim, CA, USA, May 2-6, 1983); ERIC ED233314
ANDERSON, RICHARD & DAVISON, ALICE, 1986: Conceptual and Empirical Bases of Readability Formulas. Technical Report No. 392. ERIC ED281180
BACKMAN, JARL, 1976: Lix-mätning av läsbarhet eller trycksvärta? (Pedagogisk debatt 16). Umeå universitet 1976.
BAMBERGER, RICHARD & RABIN, ANNETTE T., 1984: New approaches to readability: Austrian research, The Reading Teacher, Feb. 1984, pp. 512-519
BJöRNSSON, C. H., 1968: Läsbarhet. Liber, Stockholm 1968
BJöRNSSON, C. H., 1983: Readability of Newspapers in 11 languages. Reading Research Quarterly, vol 18, summer 1983, pp. 480-487
BORMUTH, JOHN R., 1969: Readability: A new approach. Reading Research Quarterly, Spring 1969, pp 79-135
CHERRY, L. L. & VESTERMAN, W.: The STYLE and DICTION Programs (Computing Science Technical Report #91). Bell Laboratories, Murray Hill, N.J., USA, 1980.
CLARK, CHARLES H., 1981: Assessing comprehensibility: The PHAN system. The Reading Teacher, March, 1981
COHEN, MICHAEL E. & LANHAM, RICHARD A.: HOMER: Teaching Style with a Microcomputer. in The Computer in Composition Instruction: A Writer's Tool, William Wresh (Ed.), National Council of Teachers of English, Urbana, I.L.; ERIC ED241602
CONGLETON, DONNA M.1982: Development and Validation of a Scale to Measure Metaphoric Complexity. ERIC ED258185
DAVISON, ALICE, 1986: Readability -- The Situation Today. Reading Education Report No. 70. ERIC ED281166
DUFFELMEYER, FREDERICK A. 1982: A comparision of two noncomputational readability techniques. The Reading Teacher, Oct 1982.
DUFFELMEYER, FREDERICK A. 1985: Estimating readability with a computer: Beware the aura of precision. The Reading Teacher, Jan 1985.
ELLEY, WARWICK B., 1969: The assessment of readability by noun frequency counts. Reading Research Quarterly, Spring 1969,pp. 411-427
FRENCKNER, KERSTIN 1990: Legibility of continous text on computer screens -- a guide to the literature (IPLab-25). NADA, KTH, Stockholm, 1990.
FRY, EDWARD 1968: A Readbility Formula That Saves Time. Journal of Reading, April, 1968.
FRY, EDWARD 1977: Fry`s Readability Graph: Clarifications, Validity and Extension to level 17. Journal of Reading, December, 1977
FRY, EDWARD 1989: A Readability Formula for Short Passages. Version of a paper presented at the Annual Meeting of the International Reading Association (34th, New Orleans, LA, USA, April 30 - May 4, 1989); ERIC ED308492
GIBSON, WALKER 1966: Tough, Sweet and Stuffy: An Essay in Modern Prose Styles. Indiana University Press, Bloomington, IA, USA, 1966
HALLIDAY, M.A.K., & HASAN, R: Cohesion in English. London, UK: Longman, 1976
HENSINGER, JAMES S., 1988: Readability. Library Software Review, July/August 1988.
KLARE, GEORGE R.: Assessing readability. Reading research quarterly, No 1 1974-1975.
LARSSON, ROLAND: Läsbarhetprogram KIX för IBM PC, XT och AT. Scandinavian PC Systems AB, Växjö 1987, ISBN 91-86940-13-9
LARSSON, ROLAND & FRANKEL, STEVEN 1990: Corporate Voice -- A New Kind of Writing Tool. Scandinavian PC Systems Inc., Rockville, Maryland, USA
LOSA, J. W., AAGAARD, JAMES A. & KINCAID, J. PETER 1983: Readability grade levels of selected navy technical school curricula (Technical Memorandum 83-2). Training Analysis and Evaluation Group, Orlando, FL 32813, USA; ERIC ED226337
MCCLURE, GLENDA M.: Readability Formulas: Useful or Useless? IEEE Transactions on Professional Communication. No 1, Mar 1987.
OLSON, ARTHUR V., 1984: Readability Formulas -- Fact or Fiction. Reports - Research/Technical (143), ERIC ED258143
PERKINS, KYLE, 1982: The Application of a Stylistic Metric to English as a Second Language Compositions. ERIC ED225383
PERLMAN, GARY & ERICKSON, THOMAS D.: Graphical Abstractions of Technical Documents. Visible Language, No 4 1983
RASH, WAYNE JR. 1991: Corporate Style. Byte, feb. 1991.
RUSH, TIMOTHY, 1985: Assessing readability: Formulas and alternatives. The reading teacher, December, 1985
SPIEGEL, GLENN & CAMPBELL, JOHN J., 1989: Measuring Readability with a Computer: What We Can Learn. Paper presented at the Meeting of the UCLA Conference on "Computers and Writing: New Directions in Teaching and Research", Los Angeles, CA, USA, May 4-5, 1989; ERIC ED262386
SVENSSON, CAI, 1989: Index eller intresse? Linköping 1989
TAYLOR, W, 1953: Cloze procedure: A New Tool for Measuring Readability. Journalism Quarterly, no 30, 1953, pp 415-433
WHITNEY, MARGRET A., 1987: Combining Elegance and Readability: Walker Gibson's Tough, Sweet, and Stuffy. IEEE Transactions on Professional Communication, No 4, Dec 1987
Vissa av resultaten tolkas som procentandelar av en total mängd, såsom t.ex. antal passiva fraser. Fleschs R.E. tolkas som årskursnivå.
33 New Montgomery Street
Suite 1260
San Fransisco, CA 94105
USA
Verbala tolkningar presenteras till en del i resultaten, t.ex. till läsbarhetsvärdena och de genomsnittliga ord-, menings- och styckeslängderna. Läsbarhetsvärdena presenteras dessutom som horisontella stapeldiagram.
330 Townsend Street
Suite 123
San Fransisco, CA 94107
USA
De flesta värdena presenteras i KIX-programmet som stapeldiagram. "Murbruk" och "tegelstenar" motsvarar ungefär funktionsord och innehållsbärande ord.
Box 5004
350 05 VÄXJÖ
De mer komplicerade faktorerna presenteras på var sin linjalskala. De sammanfattas verbalt på en skala "Utmärkt" till "Behöver bearbetas".
132 Alpine Terrace
San Francisco Ca. 94117
USA
Alla dessa värden presenteras på var sin linjalskala med siffervärden. Dessutom presenteras tre omdömen, läsbarhet, personlig ton och händelser på en skala mellan "Usel" och "Utmärkt".
P.O. Box 5786
Bellevue WA 98006
USA
11711 N. College Ave.
Carmel
Indiana 46032
USA
Dessutom kvantifiering av såväl några syntaktiska mått (enkel, samansatt mening etc.) som ordklasser (verbformer, substantiv, prepositioner etc.) och meningsinledning (indelat i ordklasser).
CIRCLE Lab
UC Santa Barbara
(c) Regents, University of California
USA
Redovisar dessutom en sammanställning över de 30 vanligaste orden i texten och hur många gånger resp. ord använts. Frekvenslista över bokstävernas användning i texten.
(c) 1991 The Software System
I II III Correct Grammar Flesch R.E. 58.2 (9) 77.3 (6) 45.5 (13) Flesch-Kincaid grade l. 9.6 5.0 11.2 Gunning Fog Index 9.3 5.1 10.0 Gram*ma*tik Mac Flesch-Kincaid grade l. 10 5 12 Flesch R.E. 56 78 46 Maxi Read Flesch R.E. 58 (10) 79 (7) 46 (14) Sensible Grammar Flesch R.E. 50% (13) 76% (7) ? Flesch H.I. 10% 65% ? Word Count (Macintosh) Gunning Fog Index 13 8 15 Word Count (MS-DOS) Flesch R.E. 58.6 (10) 79.3 (7) 45.8 (13)